
Hi everyone,
We have a new build releasing today to Zet Universe Insiders – Build 5728.33890. This build is full of improvements to stability and quality as well as some additional UI polish. It also has one great UI feature that you've asked us for.
We have a new build releasing today to Zet Universe Insiders – Build 5728.33890. This build is full of improvements to stability and quality as well as some additional UI polish. It also has one great UI feature that you've asked us for.
Getting Started:
- If you are new to the Zet Universe Insider Program and haven't installed Zet Universe, yet, please visit the Set Up Your PC webpage to download the latest build's installer.
- Otherwise, as usual, the newest build is available via the magic of Zet Universe Update system, powered by Squirrel for Windows. To get it, you can go to Settings --> Update, and click on "Check Now" button to get it now.
- Total download might range from a few hundred kilobytes up to 12MB, depending on the number of updates you've applied already to your copy of the Zet Universe Insider Preview.
- Once the build is downloaded, Zet Universe will begin the installation. Once it will finish, it will ask you to restart the app.
WHAT'S NEW?
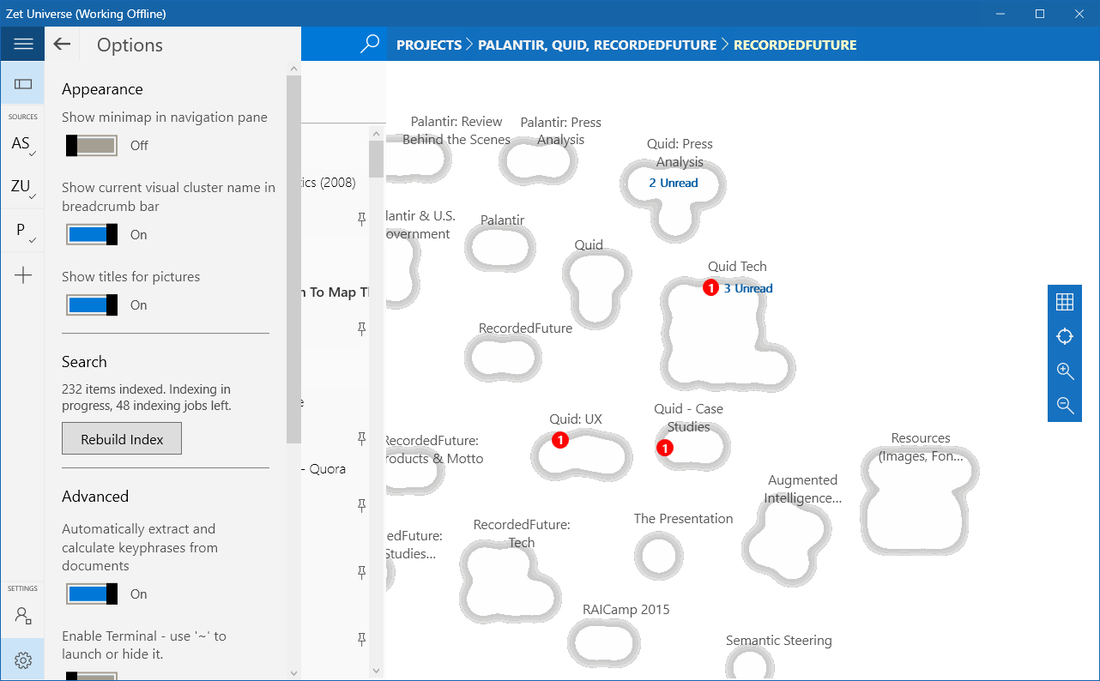
Seeing number of unread items in the project space while working in the "PROJECTS" level: We've heard a lot of requests from you, our Insiders, that not only you want to know if there is anything marked as important inside the project without opening the project, but you also want to know if there any unread items inside it. Today, we are glad to make this functionality available to you!
Seeing thumbnails for PDF files no matter if there is Adobe Acrobat Reader installed or not: As people say, it's better to see it once than hear about it hundred times. Same goes for documents thumbnails, right? We put a lot attention to making it possible for you to find documents in Zet Universe by using their thumbnails; however, thumbnail extraction from documents doesn't work always reliable, especially when using the standard Windows Shell APIs. There are multiple reasons for that, and in our effort to make Zet Universe generally more stable, we've added a custom PDF document thumbnail extraction processor that works independently. This processor is powered by the SyncFusion's technology, and is a newest member of the growing list of the information processors, as you can see in the third screenshot of the slideshow below.
Option to show/hide PDF thumbnails is removed from Options: In the past, problems with Adobe Acrobat Reader integration with the Windows Shell could lead to Zet Universe crashes on some of our customers' machines. Now, as we've introduced a custom PDF document thumbnail extraction processor, we no longer have to keep this option in the product.
General UX improvements and refinement: You’ll continue to see general UX improvements and refinement in this build. The main UX improvement in this build is new item thumbnail cache, rewritten from scratch. Our brand-new thumbnail cache uses an aggressive strategy in order to make sure you'll get the thumbnails for documents you've imported into Zet Universe. It falls back to the Windows Shell APIs only when it can't handle documents (e.g., Office files), persists extracted thumbnails to the disk upon application shutdown, and extracts new thumbnails only when underlying data sources have been changed after the last thumbnail extraction date. This last feature of the new cache leads to less calls to both Windows Shell APIs and to the individual files on the disk drive on subsequent application launches, making overall application performance more predictable and stable.
Semantic Pipeline is now publishing all items for further processing on each application launch: In the coming weeks, we will also be flighting the Zet Universe SDK. Our goal is to provide developers among our Insiders with ability to further extend Zet Universe Insider Preview with new data sources, as well as the new data extractors, classifiers, and analyzers. Our platform currently provides two extension points, allowing introduction of new data sources (we call them "applications") and new data processors (which could extract, classify, or further analyze given data items).

Last week we've introduced our second data source, the "Local Folders" application, which enabled you to connect your local folders and files to your Zet Universe project spaces. This week we're introducing another data processor, the "PDF Document Extraction Processor". Although we've already provided Zet Universe with a few other processors which do such things as full-text and keyphrase extraction, web page download and thumbnail extraction, kind classification, and other things, the PDF document extraction processor is a bit unique as it follows the model that will be standard for the rest of the 3rd party information processors.
Starting with this flight, on each application startup as well as upon each kind extraction for new items (files/web pages/etc.), Zet Universe publishes all items to the Semantic Pipeline to a special address, "/Topics/Classifications/Kinds/". Each information processor subscribes to this address in the Pipeline and processes each new item asynchronously. For instance, our new PDF document extraction processor checks each incoming item for its kind, and if its kind is "Document", and it has a corresponding local PDF file, our processor tries to load this file. If succeeded, it extracts both small and large thumbnails of its first page and saves them into our brand new item thumbnail cache (also introduced with this build). Otherwise, it skips the item. The whole process is asynchronous, and each processor works in its own background thread, separating intensive data processing tasks from the user interface.
Starting with this flight, on each application startup as well as upon each kind extraction for new items (files/web pages/etc.), Zet Universe publishes all items to the Semantic Pipeline to a special address, "/Topics/Classifications/Kinds/". Each information processor subscribes to this address in the Pipeline and processes each new item asynchronously. For instance, our new PDF document extraction processor checks each incoming item for its kind, and if its kind is "Document", and it has a corresponding local PDF file, our processor tries to load this file. If succeeded, it extracts both small and large thumbnails of its first page and saves them into our brand new item thumbnail cache (also introduced with this build). Otherwise, it skips the item. The whole process is asynchronous, and each processor works in its own background thread, separating intensive data processing tasks from the user interface.
SOME KNOWN ISSUES
- You can't drop items from other project spaces by using search results... Just yet. Instead, you'll get an error message.
- Zet Universe still doesn't re-connect after waking up if it had no internet connection before the computer went to hibernation.
- There is no UI to change the default file store when multiple file store data sources are added to the project space. Zet Universe will use the first added data source to save files you've added to the project space.
HERE ARE SOME THINGS WE FIXED
- Verbose logging is fixed and should be working as usual in this build.
IN CLOSING
We hope you enjoy using this build, and keep sending us feedback!
Thanks,
Daniel and the team
Thanks,
Daniel and the team
 RSS Feed
RSS Feed
